超高速シリアライズフォーマット「DLHN」
2022/05/09

新しいシリアライズフォーマットDLHNをリリースしました。
DLHNは高速でデータサイズが小さいバイナリ形式のシリアライズフォーマットです。
DLHNの発音は"Dullahan"と同じです。
公式サイトは https://dlhn.org
実装は https://github.com/otake84/dlhn
イラストは @kira2beat さんに描いていただきました。
特徴
DLHNはプログラミング言語やプラットフォームに依存しないバイナリ形式のシリアライズフォーマットで、JSON, CSV, MessagePack, Protocol Buffersなどから影響を受けています。
シリアライズとデシリアライズが高速で、データサイズが小さく、Schema定義ファイルが不要でストリーム処理にも対応しています。
これを聞くとMessagePackと同じように感じるかもしれませんが、実際のデータ構造は上記のフォーマットの中ではCSVが一番似ているかなと僕は思っています。
DLHNはCSV同様ヘッダーとボディがありそれぞれを分離することが可能なためです。
ひとつのヘッダー情報を複数のボディに使い回すことが可能なのでストリームデータとの相性が非常に良いと思います。
ベンチマーク
フォーマットそのものが異なるため完全な同一条件でのベンチマークを取ることは難しいのですが、JSON ( serde_json )、Protocol Buffers ( prost )、MessagePack ( rmp-serde )と比較してみたところDLHNが最速でした。
使用したベンチマーク https://github.com/otake84/dlhn/tree/main/dlhn_bench
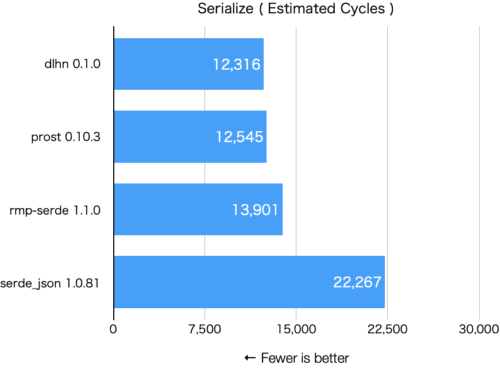
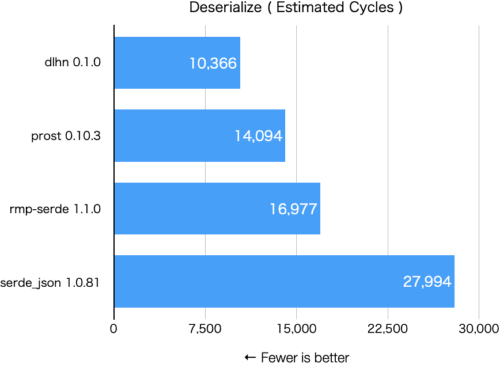
Rust 1.60, M1 Mac mini
Fewer is better
# dlhn 0.1
serialize_dlhn
Instructions: 5688
L1 Accesses: 8151
L2 Accesses: 35
RAM Accesses: 114
Estimated Cycles: 12316
deserialize_dlhn
Instructions: 4669
L1 Accesses: 6761
L2 Accesses: 42
RAM Accesses: 97
Estimated Cycles: 10366
# prost 0.10.3
serialize_protobuf
Instructions: 5758
L1 Accesses: 8240
L2 Accesses: 28
RAM Accesses: 119
Estimated Cycles: 12545
deserialize_protobuf
Instructions: 6385
L1 Accesses: 9109
L2 Accesses: 31
RAM Accesses: 138
Estimated Cycles: 14094
# rmp-serde 1.1.0
serialize_messagepack
Instructions: 6061
L1 Accesses: 8706
L2 Accesses: 38
RAM Accesses: 143
Estimated Cycles: 13901
deserialize_messagepack
Instructions: 6629
L1 Accesses: 9387
L2 Accesses: 41
RAM Accesses: 211
Estimated Cycles: 16977
# serde_json 1.0.81
serialize_json
Instructions: 9123
L1 Accesses: 12742
L2 Accesses: 64
RAM Accesses: 263
Estimated Cycles: 22267
deserialize_json
Instructions: 12711
L1 Accesses: 18194
L2 Accesses: 70
RAM Accesses: 270
Estimated Cycles: 27994
高速でデータサイズが小さい理由
ヘッダーとボディを分離できる
アプリケーション側が事前に型情報を知っている場合、ヘッダーが必要ないためボディのみをシリアライズといったことができます。
可能な限りシリアライズするものを減らしている
例えば構造体やクラスなどをシリアライズする際に、JSONやMessagePackの場合はフィールド名と値を、Protocol Buffersの場合はフィールドごとに割り振られた番号と値をシリアライズする必要があるのですが、DLHNでは単にフィールドが宣言された順に値のみをシリアライズするだけです(ただし、この方法は高速な代わりに互換性の問題が発生する可能性があります)
8bit整数
DLHNの8bit整数は単にリトルエンディアンでエンコードするだけなため、高速な上に1バイトで0~255(符号付きの場合は-128~127)まで表現できます。
PrefixVarint
8bit以外の全ての整数のエンコードにPrefixVarintを採用しています。
これに関しては実装の問題かもしれないのですが、PrefixVarintとProtocol Buffersで使用されているLEB128を両方実装し、ベンチマークしてみたところPrefixVarintのほうがわずかにですが高速でした。
DateやDateTime型
APIのレスポンスなどでDateやDateTimeをよく使うと思うのですが、DLHNでは効率的にシリアライズできるように専用の型を用意しています。
データにもよりますがJSONでISO 8601などを使ってシリアライズする場合と比較してDLHNでは数分の一にまでデータサイズを削減できます。
型について
DLHNでは以下のような豊富な種類の型を用意しています。
Boolean
Booleanです。
Optional<T>
T型の値を最大一つ格納できます。
Some(T)またはNoneを格納できます。
Unit
なにもない特殊な型です。
ボディ部は0バイトです(なにもありません)
nullableにしたい場合はUnitではなくOptionalを使用してください。
UInt8
8bit符号なし整数です。
UInt16
16bit符号なし整数です。
UInt32
32bit符号なし整数です。
UInt64
64bit符号なし整数です。
Int8
8bit符号付き整数です。
Int16
16bit符号付き整数です。
Int32
32bit符号付き整数です。
Int64
64bit符号付き整数です。
Float32
IEEE 754形式の32bit浮動小数点型です。
Float64
IEEE 754形式の64bit浮動小数点型です。
BigUInt
符号なしBigIntです。
BigInt
符号付きBigIntです。
BigDecimal
任意精度の符号付き10進数です。
String
UTF-8形式の文字列です。
Binary
バイト列です。
画像や動画、音声などといったバイナリデータを格納できます。
Array<T>
T型の値を任意の数格納できます。
Tuple(T1, T2, T..)
Tupleです。
格納できる値の数が固定でフィールドごとに別の型をつけられます。
ユーザーが定義した型をシリアライズする場合もTuple型を使用します。
Map<T>
T型の値を持つMap型です。
KeyはStringのみ使用できます。
Date
日付を格納できます。
DLHNのDate型は内部で年と日付に別れています。
年の部分は2000年を基準とした32bit符号付き整数をPrefixVarintとZigZag encodingでエンコードしたもの、日付部分は1月1日を0としてそこからの経過日数ごとに1ずつ増加する16bit符号なし整数をPrefixVarintでエンコードしたものを格納しています。
日付によってサイズが変わりますが、例えば2030年04月01日であれば 0x3c5a となり、たった2バイトで表現することができます。
JSONでISO 8601形式にする場合 ”2030-04-01” と12バイト(ダブルクォート含む)になるのでDLHNの場合6分の1にまでデータサイズを削減できます。
1970年からではなく2000年からにした理由ですが1970年からにした場合、年部分を1バイトで表現できるのが 1906~2033年なのに対して2000年からにした場合 1936~2063年 となり今から40年後くらいまでは1バイトで表現できるのと、1936年まであれば多くの人の生年なども1バイトで表現できると思ったためです。
DateTime
DateTime型は 1970-01-01 00:00:00.000000000 (UTC) を基準とし、内部で 1970-01-01 00:00:00 からの経過秒数(64bit符号付き整数をPrefixVarintとZigZag encodingでエンコードしたもの)と、ナノ秒(符号なし32bit整数をPrefixVarintでエンコードしたもの)に別れています。
JSONで 2022-01-01 01:23:45.012345678をIOS 8601形式で表現する場合 "2022-01-01T01:23:45.012345678+00:00" と37バイト(ダブルクォート含む)必要ですが、DLHNの場合 0xf248eb7318ee14c60b と9バイトで表現できます。
エンディアンについて
現代のCPUは基本的にリトルエンディアンで動作しているためDLHNではリトルエンディアンを採用しました。
整数のエンコーディングについて
Protocol BuffersではLEB128とZigZag encodingを組み合わせたものを採用していますが、DLHNではPrefixVarintとZigZag encodingを組み合わせたものを採用しています。
PrefixVarintはLEB128と比較すると先頭1バイトを見れば全部で何バイトのデータなのかわかったり、64bit整数が最大9バイトで表現できる(LEB128は最大10バイト必要)などの利点がありますが、最大でも64bit整数までしか表現できないといった欠点があります。
最初はDLHNでもProtocol Buffersと同様のエンコードをしていたのですが、試しにPrefixVarintに変更してみたところ数%ですが高速化されたためこちらを採用しました。
ただし単純に実装の問題だった可能性があるため必ずしもPrefixVarintのほうが高速とは残念ながら言い切れません。
8bit整数(符号なし符号あり両方とも)は例外的にPrefixVarintやZigZag encodingを使用せず、単純にリトルエンディアンでエンコードするだけです。
なぜStruct型がないのか
元々DLHNにもStruct型はあったのですがTuple型と同じ仕様だったため一旦なくしました。
StructやClassなどをシリアライズする際はフィールドが定義された順にTupleと同じ方法でシリアライズします。
DLHNの場合ヘッダーとボディをセットにすることも可能なためなんとかなるのではないかなと思っていますが、将来的にProtocol Buffersのような仕組みで復活させるかもしれません。
独自定義の型について
DLHNにはMessagePackのような独自定義型専用のExtension型は用意していませんが、Tuple型で代用できます。
例えば以下のような独自定義の型があった場合はフィールドが定義された順に Tuple(UInt64, String, Date) と同じ方法でシリアライズします。
struct Example {
id: UInt64,
name: String,
birthday: Date,
}
Map型のキーにStringしか使えない理由
一部のプログラミング言語では浮動小数点型などをMapのキーに指定できないためです。
解析されにくい
これについてはたまたまそうなっただけなのですが、APIのレスポンスにボディのみのDLHNを入れるとそのデータになんの情報が含まれているかぱっと見ではわからず解析が難しくなって結果的に競合サービスなどからデータをごっそり持っていかれるみたいなことを防げるかもしれません。
検討中のもの
- 128bit整数型
- 16bit、128bit浮動小数点型
- Either型
- Protocol BuffersのようなStruct型
- IDL
- 拡張子
- MIMEタイプ
- meta情報を入れられるようにする(これを使ってProtocol BuffersのStruct型のようなことをするのもありかも…?)
